Mielenterveysdiagnooseja voidaan ennustaa koneoppimisen avulla
Lähtökohdat Mielenterveysongelmat ovat merkittävä haaste työterveydelle. Analysoimme yleisluontoisen työterveyskyselyn vastausten ja mielenterveysdiagnoosien välistä yhteyttä koneoppimiseen perustuvalla luokittelulla.
Menetelmät Aineistona olivat 11 828 työterveyshuollon asiakkaan työterveyskyselyt sekä mielenterveysdiagnoosit. Ohjatun koneoppimisen XGBoost-luokittelijalla pyrittiin ennustamaan kyselyistä, saako henkilö diagnoosin kahden vuoden seurantajakson aikana.
Tulokset Sekä kaikkiin kyselyn kysymyksiin että seitsemään tärkeimpään kysymykseen perustuvat mallit ennustivat diagnooseja selvästi paremmin kuin ikään ja sukupuoleen perustuva triviaalimalli tai satunnaisluokittelija. Tärkeimmät diagnoosia ennustavat kysymykset liittyivät stressiin, surumielisyyteen ja väsymykseen.
Päätelmät Koneoppimisella onnistuttiin tunnistamaan mielenterveysongelmia ennustavia tekijöitä. Ongelman kannalta tärkeimmät kysymykset voidaan seuloa automaattisesti. Lähestymistapa saattaa osoittautua hyödylliseksi myös muissa työterveyden ja -turvallisuuden tutkimuksissa.
Mielenterveysongelmista on useiden indikaattorien mukaan tullut kasvava ongelma länsimaissa (1). Suomessa menetetään mielenterveyteen liittyvien haasteiden takia vuosittain miljoonia työpäiviä. Sekä työkyvyttömyyseläkkeissä että Kelan korvaamissa pidemmissä sairauspoissaoloissa mielenterveyssyyt ovat osuudeltaan suurin yksittäinen ryhmä (2,3). Lisääntyneiden ongelmien varhainen havaitseminen ja niihin puuttuminen on työterveyshuollon kannalta yhä tärkeämpää (4) varsinkin nuoremmissa ikäluokissa ja etenkin nuorilla naisilla (2,5,6).
Kansainvälisessä tutkimuskirjallisuudessa on useaan otteeseen todettu koneoppimismenetelmien kyky tehokkaaseen mielenterveyshäiriöitä selittävien tekijöiden tunnistamiseen, sairauksien ennakointiin sekä riskihenkilöiden seulomiseen (7,8). Alan tutkimus on silti vielä melko alkutekijöissään, eikä työväestön mielenterveyttä ole laajasti analysoitu koneoppimismenetelmillä (9,10). Uudelle tutkimukselle on siis vielä runsaasti tilaa.
Työterveyshuollon terveystarkastuksilla pyritään ensisijaisesti työkyvyn edistämiseen ja työkyvyttömyyden ehkäisemiseen, ja ne soveltuvatkin hyvin mielenterveysongelmien varhaiseen havaitsemiseen. Erilaiset terveystarkastusprosessin käynnistävät seulovat kyselyt työkyvyn menettämisriskissä olevien löytämiseksi ovat tulleet yhä suositummiksi. Kyselyiden ennustearvosta sairauspoissaoloille ja pysyvälle työkyvyttömyydelle on aikaisempaa näyttöä (11,12).
Tässä tutkimuksessa yhdistämme työterveyskyselyn vastauksia kohdehenkilöiden mahdollisesti saamiin mielenterveysdiagnooseihin koneoppimiseen perustuvilla luokittelumallinnuksilla. Tutkimuskysymyksemme ovat: 1) mitkä kyselyyn sisältyvät taustamuuttujat ja kyselystä esiin nousevat piirteet parhaiten ennustavat mahdollisia jatkossa ilmeneviä mielenterveyden ongelmia ja 2) millä tarkkuudella luokittelumallinnus kykenee ennustamaan tulevat mielenterveyden diagnoosit?
Aineisto ja menetelmät
Lähtöaineistot
Tutkimuksessa käytetty työterveyskyselyaineisto koostui Terveystalon työterveysasiakkailleen lähettämästä kyselystä (liite 1) liittyen asiakkaan terveydentilaan, elämäntapoihin, työhyvinvointiin ja työoloihin. Kysely täytetään yleisimmin työhöntulotarkastuksessa sekä työsuhteen aikana noin 3–5 vuoden välein tehtävässä vapaaehtoisessa terveystarkastuksessa. Aineistoon valittiin kaikki 18–64-vuotiaat henkilöt, joille kysely oli tehty aikavälillä 8.8.2016–31.12.2017. Kyselymuuttujia sisällytettiin analyysiin 104 kpl.
Diagnoosiaineistoon valittiin ne 18–64-vuotiaat henkilöt, joille oli Terveystalon järjestelmiin kirjattu rakenteisessa muodossa mielenterveysperustainen hoitokäynti vuosilta 2012–2019. Aineistoon sisällytettiin diagnoosit F30–F39 (Mielialahäiriöt), F40–F48 (Neuroottiset, stressiin liittyvät ja somatoformiset häiriöt), F51 (Ei-elimelliset unihäiriöt) ja Z73.0 (Työuupumus (burnout)).
Aineiston mukaan ennen kyselyn täyttämistä diagnoosin saaneet henkilöt poistettiin, ja useammista saman henkilön kyselyvastauksista huomioitiin vain viimeisin ennen mahdollista ensimmäistä diagnoosia täytetty kysely. Näin saadun aineiston tiedot on esitetty taulukossa 1 (alkuperäinen aineisto).

Seuranta-aika työterveyskyselyn täyttämisestä mahdollisen mielenterveysdiagnoosin saamiseen rajattiin kahteen vuoteen, jotta kyselyvastausten voitiin katsoa vielä olevan olennaisia mahdollisen diagnoosin kannalta. Alkuperäisestä aineistosta suodatettiin pois henkilöt, jotka 1) eivät olleet olleet Terveystalon työterveysasiakkaina yhtäjaksoisesti vähintään puolta vuotta ennen kyselyn täyttämistä ja kyselyn täyttämisen jälkeen joko kahta vuotta tai ennen sitä saatuun diagnoosiin asti tai 2) olivat saaneet diagnoosin yli kaksi vuotta kyselyyn vastaamisen jälkeen (taulukko 1, suodatettu aineisto).
Luokittelu ja evaluointi
Aineiston luokitteluun sovellettiin ohjatun koneoppimisen gradient boosting -pohjaista XGBoost-luokittelijaa (eXtreme Gradient Boosting) (13,14). Menetelmä on kuvattu tarkemmin liitteessä 2.
Aineistosta 20 % erotettiin diagnoosin saamisen suhteen ositetulla satunnaisotannalla testidatajoukoksi, ja loput 80 % käytettiin mallin opettamiseen ja validointiin. Opetus- ja validointidata jaettiin edelleen ristivalidoinnissa kymmeneen osaan vastaavasti ositetulla otannalla, ja validointi toistettiin viisi kertaa eri jaoilla. Opetus- ja validointiprosessin jälkeen lopullinen luokittelumalli opetettiin koko opetus- ja validointidatalla, ja mallin suorituskyky laskettiin alussa erotetulla testidatalla.
Luokittelutuloksien evaluointiin hyödynnettiin ROC-käyrää (Receiver Operating Characteristic) ja sen alle jäävää pinta-alaa (Area Under Curve, AUC) (15,16). Tulosten merkitsevyyden tarkasteluun käytettiin lisäksi AUC-pinta-alan keskivirhettä ja luottamusväliä, jotka laskettiin ei-parametrisella menetelmällä (17).
Aineiston käsittely ja analyysi suoritettiin Python 3 -ympäristössä (v. 3.6.9) pakettien Scikit-Learn (v. 0.24.1) ja XGBoost (v. 1.4.2) avulla (14,18).
Tutkimuslupa ja tietosuoja
Tutkimusluvan hankkeelle myönsi sosiaali- ja terveysalan tietolupaviranomainen Findata (päätös Dnro THL/1935/14.02.00/2020). Aineisto pseudonymisoitiin ennen analyyseja, ja aineiston käsittelyssä hyödynnettiin vahvoja tietoturvakäytäntöjä. Terveystalon tietosuojavastaava arvioi aineiston ennen sen luovuttamista tutkimuskäyttöön.
Tulokset
Luokitteluongelma muodostettiin siten, että kyselytutkimusaineistolla pyrittiin ennustamaan henkilön todennäköisyyttä saada mikä tahansa aineistoon sisällytetty mielenterveysdiagnoosi seuranta-ajan kuluessa kyselyn täyttämisestä.
Mallinnuksen lähtökohdaksi valittiin kaikkien piirteiden eli kaikkien työterveyskyselyn kysymysten sisällyttäminen malliin. Opetettu XGBoost-malli sisältää tiedon piirteiden merkittävyydestä, jolloin vähemmän tärkeitä piirteitä voidaan karsia täyden mallin opetuksen jälkeen. Näin muodostettiin vaihtoehtoinen malli seitsemällä tärkeimmällä piirteellä. Kyselytutkimuksen arvoa diagnoosien ennustamisessa arvioitiin vertailemalla malleja satunnaiseen luokittelijaan sekä triviaaliin sukupuolen ja ikään perustuvaan malliin.
Luokittelutulokset
Kuvio 1 esittää eri piirrevalinnoilla saatujen mallinnustulosten vertailun ROC-käyrinä. Kuvaajan vaaka-akselina on väärien positiivisten osuus ja pystyakselina oikeiden positiivisten osuus eli herkkyys. Mitä suurempi kuvaajan alle jäävä pinta-ala on, sitä paremmin malli suoriutuu luokittelusta. Satunnaisen luokittelijan (nollahypoteesi) ROC-käyrä on suora ja AUC-arvo 0,5. AUC-pinta-alat ja niiden vertailu nollahypoteesiin on esitetty taulukossa 2.


Tulosten perusteella triviaali, sukupuoleen ja ikään perustuva malli pystyy jo selvästi parempaan suorituskykyyn kuin satunnaisluokittelija. Kaikkia kyselytutkimuksen kysymyksiä hyödyntävä malli suoriutuu parhaiten, ja seitsemän tärkeimmän piirteen mallillakaan suorituskyky ei merkittävästi heikkene, vaikka malli on huomattavasti yksinkertaisempi.
Alaryhmissä kaikkien piirteiden malli tuottaa naisille hieman heikomman luokittelutuloksen, mutta sekä alle 40-vuotiaiden että yli 40-vuotiaiden ryhmissä luokittelutulos on koko aineistoa parempi. Tämä johtunee ikäryhmien yhtenäisyydestä verrattuna koko aineistoon, jolloin luokittelutehtävä on helpompi.
Mallien hyvyyttä voidaan arvioida myös valitsemalla kiinteä herkkyysarvo ja tarkastelemalla siihen liittyvää tarkkuutta. Jos herkkyydeksi halutaan esimerkiksi 0,6 (eli 60 % todellisista mielenterveysdiagnooseista ennustetaan mallin perusteella oikein), on tarkkuus tasolla 0,69 täydellä mallilla ja 0,67 seitsemän piirteen mallilla. Tämä tarkoittaa siis, että henkilöistä, jotka eivät saa mielenterveysdiagnoosia, noin 67–69 % saa oikean luokittelutuloksen piirteiden määrästä riippuen.
Piirteiden tärkeys
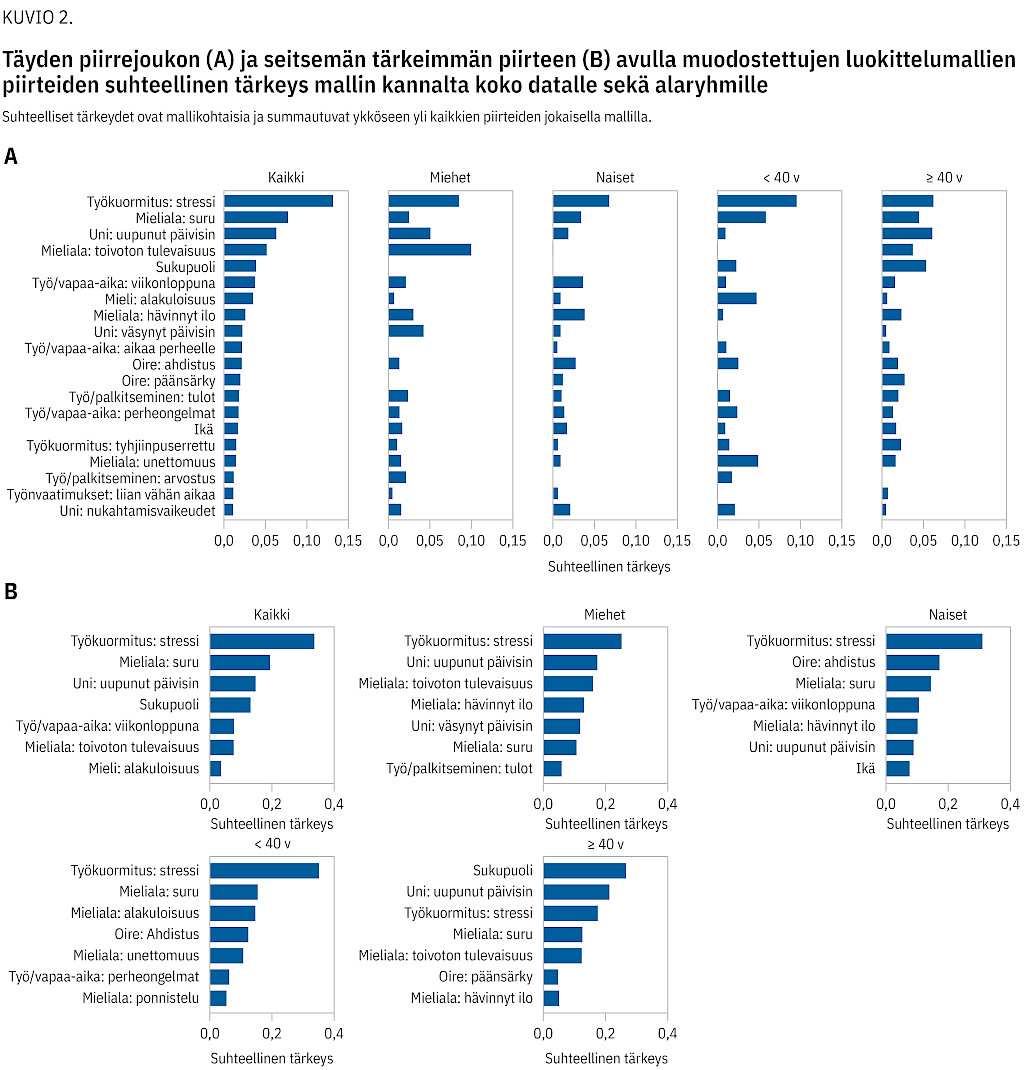
Kuvio 2 näyttää eri mallien käyttämien piirteiden suhteellisen tärkeyden mallin laskeman ennusteen kannalta. Täyden mallin piirteistä on kuvaajassa esitetty selvyyden vuoksi vain 20 tärkeintä. Niissä korostuvat stressin ja väsymyksen sekä surun ja alakuloisuuden merkitys. Myös vapaa-ajan riittävyyden ja sukupuolen vaikutus näkyy selvästi.
Alaryhmistä päiväajan uupumukseen liittyvä kysymys korostuu yli 40-vuotiailla kaikkien piirteiden mallissa, mutta alle 40-vuotiailla se ei ole merkittäviä luokittelun kannalta. Miesten kohdalla mielialakysymyksistä seitsemän tärkeimmän joukkoon nousevat muista ryhmistä poiketen työstä saadut tulot. Seitsemän tärkeimmän piirteen malleissa yhteinen tärkein piirre on puolestaan stressin tunteminen lukuun ottamatta yli 40-vuotiaita.
Päätelmät
Tutkimuksessa selvitettiin työterveyskyselyvastausten ja tulevan mielenterveysdiagnoosin saamisen välistä ajallista yhteyttä Suomen suurimman yksityisen työterveyshuollon työterveysasiakkailla. Kyselyvastausten avulla opetettu luokitin pystyi selvästi parempaan luokitteluun kuin satunnainen luokittelija tai pelkkiin triviaalitietoihin perustuva luokitusmalli. Tämä osoittaa, että vaikka kyselyä ei ole erikseen tarkoitettu mielenterveysongelmien seulomiseen, se kuitenkin kykenee tuottamaan mielenterveyden hoitotarpeen kehittymistä ennakoivaa tietoa.
Ennustemallinnusten perusteella vaikuttaa siltä, että tulevaa mielenterveysdiagnoosia ennustivat parhaiten kysymykset stressin tuntemisesta, päiväajan väsymyksestä sekä surumielisyydestä. Selittävissä tekijöissä oli kuitenkin eroja ikä- ja sukupuoliryhmien välillä, ja esimerkiksi toivottoman tulevaisuuden kokemus ennusti diagnoosia enemmän miehillä kuin naisilla. Sukupuolella ja iällä myös itsellään oli tulevaan diagnoosiin liittyvää ennustearvoa.
Luokittimen kyky ennustaa tulevaa mielenterveyden diagnoosia jäi kuitenkin suhteellisen vaatimattomaksi. Vaikuttaa siltä, että pelkkien kyselyvastausten sekä iän ja sukupuolen avulla ei vielä voi ennustaa mielenterveysdiagnoosia täysin luotettavasti yksittäisissä tapauksissa. Ennuste on nähtävä pikemminkin suuntaa antavana.
Merkittävä rajoitus tutkimusasetelmassa oli se, että analyyseihin sisällytettiin vain Terveystalon järjestelmiin kirjatut mielenterveysdiagnoosit. Osa aineiston henkilöistä on kuitenkin saattanut hakea hoitoa muulta palveluntuottajalta, jolloin osa diagnooseista ei ole sisältynyt aineistoon. Toisaalta mielenterveyden kannalta huolestuttavat kyselyvastaukset saattavat lisätä työterveyshuollossa toimia, jotka kasvattavat puolestaan mielenterveyteen liittyviä rekisteröityjä tapahtumia (esim. lääkärin diagnooseja). Nämä ilmiöt voivat osaltaan selittää luokittimen taipumusta yliennustaa diagnoosien määrää tutkimusväestössä suhteessa havaittuihin diagnooseihin.
Aikaisempia esimerkkejä koneoppimismallien hyödyntämisestä työväestön mielenterveysdiagnoosien ennustamisessa pitkittäistutkimuksessa ei kansainvälisestä tutkimuskirjallisuudesta juuri löydy. Muihin väestöryhmiin kohdistuvissa tutkimuksissa puolestaan on harvoin hyödynnetty kliinisesti määriteltyä mielenterveyshäiriötä, vaan niiden tilalla on hyödynnetty kyselyaineistoja. Esimerkiksi Ashley Tate ym. (19) pyrkivät ennustamaan rekisteritietojen pohjalta nuorten itsearvioituja mielenterveyden haasteita saavuttaen ennustearvoja, jotka olivat lähellä omia mallinnuksiamme.
Datatieteisiin perehtynyt sosiologian professori Christopher Bail (20) arvioi muutamia vuosia sitten, että datalähtöiset lähestymistavat ja laskennalliset tieteet eivät tule korvaamaan perinteisiä tutkimustapoja sosiaalitieteissä. Datatieteen mahdollisuuksia on kuitenkin alettu viime aikoina soveltaa tuloksekkaasti esimerkiksi psykiatrian (21) ja syöpätutkimuksen (22) alueella. Toisaalta työhön ja mielenterveyteen liittyvien laadukkaiden koneoppimiseen perustuvien tutkimusten määrä on toistaiseksi hyvin rajallinen (10).
Koneoppimiseen liittyvät uudet lähestymistavat mielenterveyden ja työkyvyn tutkimuksen alueella voivat kyseenalaistaa yksinomaan ennalta rajattuun dataan perustuvia tutkimushavaintoja, vahvistaa mielenterveyden oikea-aikaista hoitoa ja edesauttaa psyykkiseen työkykyyn liittyvää kehittämistoimintaa. Sillä voi olla vaikutuksia niin tieteelliseen tutkimukseen kuin käytännön työterveyden kehittämistyöhön. Esimerkiksi mielenterveyden hoitotarpeiden ennakointia on mahdollista hyödyntää palveluntuottajien asiantuntijaresurssien paremmassa kohdentamisessa.
Tietokoneiden laskentatehon ja koneoppimisen menetelmien kehitys voi edesauttaa työlääketiedettä, työturvallisuuden tutkimusta ja muita tieteenaloja lisäämään sekä systemaattisesti kerättyjen (esim. hyvinvointikyselyt) että luonnollisesti kertyvien aiemmin hyödyntämättömien datojen käyttöä. Tämä voi parhaimmillaan lisätä työkykyä tukevien järjestelmien joustavuutta, kun työntekijään, työorganisaatioon ja hyvinvointiin liittyvistä digitaalisista aineistoista voidaan tuottaa esimerkiksi työyksiköihin tai ammattiryhmiin liittyviä ennustemalleja ja automatisoituneita hälytysmerkkejä.
Työkyvyn tukemiseen pelkät datavirtakoosteet ja korrelaatioihin perustuvat ennustemallit eivät jatkossakaan kuitenkaan riitä, vaan työkyvyn johtaminen ja työhyvinvoinnin tuki tarvitsevat osaavia ja riittävästi resursoituja ihmisiä tekemään työntekijöiden hyvinvointia tukevia arkisia tekoja.
Kirjoittajien ilmoittama käsikirjoitukseen liittyvä rahoitus: Työsuojelurahasto 190402
Liite 1. Työterveyskyselyn kuvausLiite 2. XGBoost-menetelmä
Olli Haavisto, Ari Väänänen, Pekka Varje: Palkkiot osallistumisesta tutkimuksen toteutukseen, korvaus käsikirjoituksen kirjoittamisesta tai tarkistamisesta (Työsuojelurahasto, tutkimushankkeen rahoittaja).
Simo Taimela, Ara Taalas: Ei sidonnaisuuksia.
Oskar Niemenoja: Palkkiot osallistumisesta tutkimuksen toteutukseen (Suomen Terveystalo), osakkeet/optiot (Suomen Terveystalo).
Niina Nieminen: Palkkiot osallistumisesta tutkimuksen toteutukseen (Suomen Terveystalo).
Tämä tiedettiin
• Työväestön mielenterveysongelmien varhainen tunnistaminen ja niihin puuttuminen on yhä tärkeämpää.
• Koneoppimismenetelmillä on mahdollista analysoida mielenterveysongelmia, mutta erityisesti työväestön terveydessä on vielä paljon tutkittavaa.
• Itsearviointiin perustuvat työterveyskyselyt auttavat muun muassa sairauspoissaolojen ja pysyvän työkyvyttömyyden ennustamisessa.
Tutkimus opetti
• Yleisen työterveyskyselyn vastauksista on mahdollista löytää koneoppimismenetelmillä mielenterveysdiagnooseihin spesifisti liittyvää tietoa.
• Tärkeimmät kyselyn piirteet mielenterveyden kannalta liittyvät stressin, surumielisyyden ja väsymyksen kokemuksiin.
• Koneoppimismenetelmät tarjoavat apukeinoja myös työväestön mielenterveyden tutkimukseen ja käytännön sovelluksiin.
- 1
- GBD 2017 Disease and Injury Incidence and Prevalence Collaborators. Global, regional, and national incidence, prevalence, and years lived with disability for 354 diseases and injuries for 195 countries and territories, 1990–2017: a systematic analysis for the Global Burden of Disease Study 2017. Lancet 2018;392:1789–858.
- 2
- Blomgren J, Perhoniemi R. Mielenterveyden häiriöihin perustuvien sairauspäivärahapäivien määrä kasvaa taas (10.5.2022). tutkimusblogi.kela.fi/arkisto/6636
- 3
- Laaksonen M. Työolot, työkyky ja työkyvyttömyyseläkkeelle siirtyminen (28.1.2021). www.henry.fi/ajankohtaista/blogit-ja-kuukauden-kasvo/2021/01/tyoolot-tyokyky-ja-tyokyvyttomyyselakkeelle-siirtyminen.html
- 4
- Ervasti J, Kausto J, Leino-Arjas P, Turunen J, Varje P, Väänänen A. Työkyvyn tuen vaikuttavuus Tutkimuskatsaus työkyvyn tukitoimien työkyky- ja kustannusvaikutuksista. Valtioneuvoston selvitys- ja tutkimustoiminnan julkaisusarja. Helsinki: Valtioneuvoston kanslia 2022:7.
- 5
- Laaksonen M, Blomgren J, Perhoniemi R. Mielenterveyssyistä alkavat eläkkeet ovat yleistyneet nuorilla mutta vähentyneet vanhemmissa ikäryhmissä. Suom Lääkäril 2021;76:1889–97.
- 6
- Mattila-Holappa P. Nuorten aikuisten mielenterveysperusteisen työkyvyttömyyden tausta ja muuttuva työelämä. Työpoliittinen Aikakauskirja 2021;64:51–5.
- 7
- McIntosh AM, Stewart R, John A ym. Data science for mental health: a UK perspective on a global challenge. Lancet Psychiatry 2016;3:993–8.
- 8
- Russ TC, Woelbert E, Davis KAS ym. How data science can advance mental health research. Nature Human Behaviour 2019;3:24–32.
- 9
- Tiffin PA, Paton LW. Rise of the machines? Machine learning approaches and mental health: opportunities and challenges. Br J Psychiatry 2018;213:509–10.
- 10
- Varje P, Kalliomäki-Levanto T, Turtiainen J ym. Kohti kestävämpää mielen hyvinvointia työssä: Koneoppiminen ja mielenterveystapahtumien ennakointi. Työterveyslaitos, Tietoa työstä 2022. urn.fi/URN:ISBN:978-952-391-026-3
- 11
- Pihlajamäki M, Uitti J, Arola H ym. Self-reported health problems in a health risk appraisal predict permanent work disability: a prospective cohort study of 22,023 employees from different sectors in Finland with up to 6-year follow-up. Int Arch Occup Environ Health 2020;93:445–56.
- 12
- Taimela S, Malmivaara A, Justén S ym. The effectiveness of two occupational health intervention programmes in reducing sickness absence among employees at risk: two randomised controlled trials. Occup Environ Med 2008;65:236–41.
- 13
- Chen T, He T. Higgs boson discovery with boosted trees. HEPML'14: Proceedings of the 2014 International Conference on High-Energy Physics and Machine Learning 2014;42:69–80.
- 14
- Chen T, Guestrin C. XGBoost: a scalable tree boosting system. KDD'16: Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining 2016;785–94.
- 15
- Forsström J. Testien diagnostisen arvon mittaaminen ROC-käyrän avulla. Duodecim 1995;111:237.
- 16
- Fawcett T. An introduction to ROC analysis. Pattern Recognit Lett 2006;27:861–74.
- 17
- Delong ER, Delong DM, Clarke-Pearson DL. Comparing the area under two or more correlated receiver operating characteristic curves: a nonparametric approach. Biometrics 1998;44;837–44.
- 18
- Pedregosa F, Varoquaux G, Gramfort A ym. Scikit-learn: Machine learning in Python. J Mach Learn Res 2011;12;2825–30.
- 19
- Tate AE, McCabe RC, Larsson H ym. Predicting mental health problems in adolescence using machine learning techniques. Plos One 2020;15:e0230389.
- 20
- Bail C. The cultural environment: measuring culture with big data. Theory Soc 2014;43:465–82.
- 21
- Fusal-Poli P, Hijazi Z, Stahl D ym. The science of prognosis in psychiatry: a review. JAMA Psychiatry 2018;75:1289–97.
- 22
- Zhu W, Xie L, Han J, Guo X. The application of deep learning in cancer prognosis prediction. Cancers 2020;12:603.
Predicting mental health diagnoses with machine learning based on questionnaire survey data
Background Mental health problems constitute a major occupational health challenge. In our research we analyze the associations between psychiatric diagnoses and responses to an occupational health questionnaire using a machine learning classifier.
Methods The study material included occupational health questionnaires and psychiatric diagnoses from 11,828 customers of an occupational healthcare provider. Using XGBoost, a supervised machine learning classifier, we aimed at predicting whether an individual received a psychiatric diagnosis during the first two years after answering to the occupational health questionnaire.
Results Models based on all items found in the occupational health questionnaire as well as models based on seven most important items performed markedly better in predicting the psychiatric diagnosis than a trivial model based only on age and gender or a random classifier. The most important items in the prediction were related to stress, sadness, and exhaustion.
Conclusions Using the methods of machine learning, we were able to predict psychiatric diagnoses from a general occupational health questionnaire and to automatically screen the questionnaire items most relevant to our prediction problem. The approaches we utilized may turn out to be useful in other studies in the field of occupational health and safety.
Olli Haavisto, Ari Väänänen, Pekka Varje, Simo Taimela, Ara Taalas, Oskar Niemenoja, Niina Nieminen






